

Future 是 Rust 中实现异步的基础,代表一个异步执行的计算任务,与其他语言不同的是,这个计算并不会自动在后台执行,需要主动去调用其 poll 方法。Tokio 是社区内使用最为广泛的异步运行时,它内部采用各种措施来保证 Future 被公平、及时的调度执行。但是由于 Future 的执行是协作式,因此在一些场景中会不可避免的出现 Future 被饿死的情况。
下文就将结合笔者在开发 CeresDB 时遇到的一个问题,来分析 Tokio 调度时可能产生的问题,作者水平有限,不足之处请读者指出。
问题背景
CeresDB 是一个面向云原生打造的高性能时序数据库,存储引擎采用的是类 LSM 架构,数据先写在 memtable 中,达到一定阈值后 flush 到底层(例如:S3),为了防止小文件过多,后台还会有专门的线程来做合并。
在生产环境中,笔者发现一个比较诡异的问题,每次当表的合并请求加剧时,表的 flush 耗时就会飙升,flush 与合并之间并没有什么关系,而且他们都运行在不同的线程池中,为什么会造成这种影响呢?
原理分析
为了调查清楚出现问题的原因,我们需要了解 Tokio 任务调度的机制,Tokio 本身是一个基于事件驱动的运行时,用户通过 spawn 来提交任务,之后 Tokio 的调度器来决定怎么执行,最常用的是多线程版本的调度器,它会在固定的线程池中分派任务,每个线程都有一个 local run queue,简单来说,每个 worker 线程启动时会进入一个 loop,来依次执行 run queue 中的任务。如果没有一定的策略,这种调度方式很容易出现不均衡的情况,Tokio 使用 work steal 来解决,当某个 worker 线程的 run queue 没有任务时,它会尝试从其他 worker 线程的 local queue 中“偷”任务来执行。
在上面的描述中,任务时最小的调度单元,对应代码中就是 await 点,Tokio 只有在运行到 await 点时才能够被重新调度,这是由于 future 的执行其实是个状态机的执行,例如:
async move { fut_one.await; fut_two.await; }
上面的 async 代码块在执行时会被转化成类似如下形式:
// The `Future` type generated by our `async { ... }` block struct AsyncFuture { fut_one: FutOne, fut_two: FutTwo, state: State, } // List of states our `async` block can be in enum State { AwaitingFutOne, AwaitingFutTwo, Done, } impl Future for AsyncFuture { type Output = (); fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<()> { loop { match self.state { State::AwaitingFutOne => match self.fut_one.poll(..) { Poll::Ready(()) => self.state = State::AwaitingFutTwo, Poll::Pending => return Poll::Pending, } State::AwaitingFutTwo => match self.fut_two.poll(..) { Poll::Ready(()) => self.state = State::Done, Poll::Pending => return Poll::Pending, } State::Done => return Poll::Ready(()), } } } }
在我们通过 AsyncFuture.await 调用时,相当于执行了 AsyncFuture::pool 方法,可以看到,只有状态切换(返回 Pending 或 Ready) 时,执行的控制权才会重新交给 worker 线程,如果 fut_one.poll() 中包括堵塞性的 API,那么 worker 线程就会一直卡在这个任务中。此时这个 worker 对应的 run queue 上的任务很可能得不到及时调度,尽管有 work steal 的存在,但应用整体可能有较大的长尾请求。
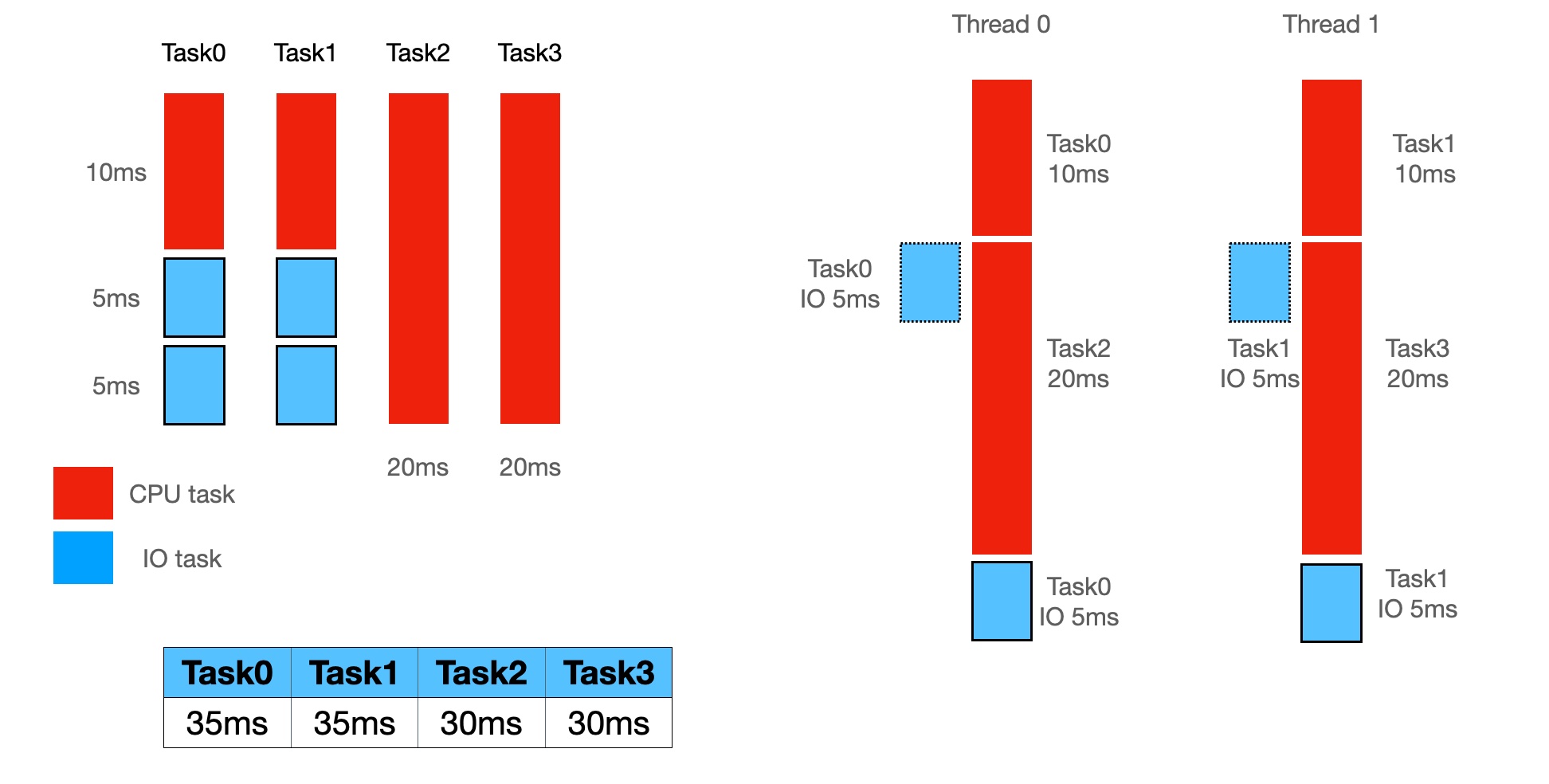
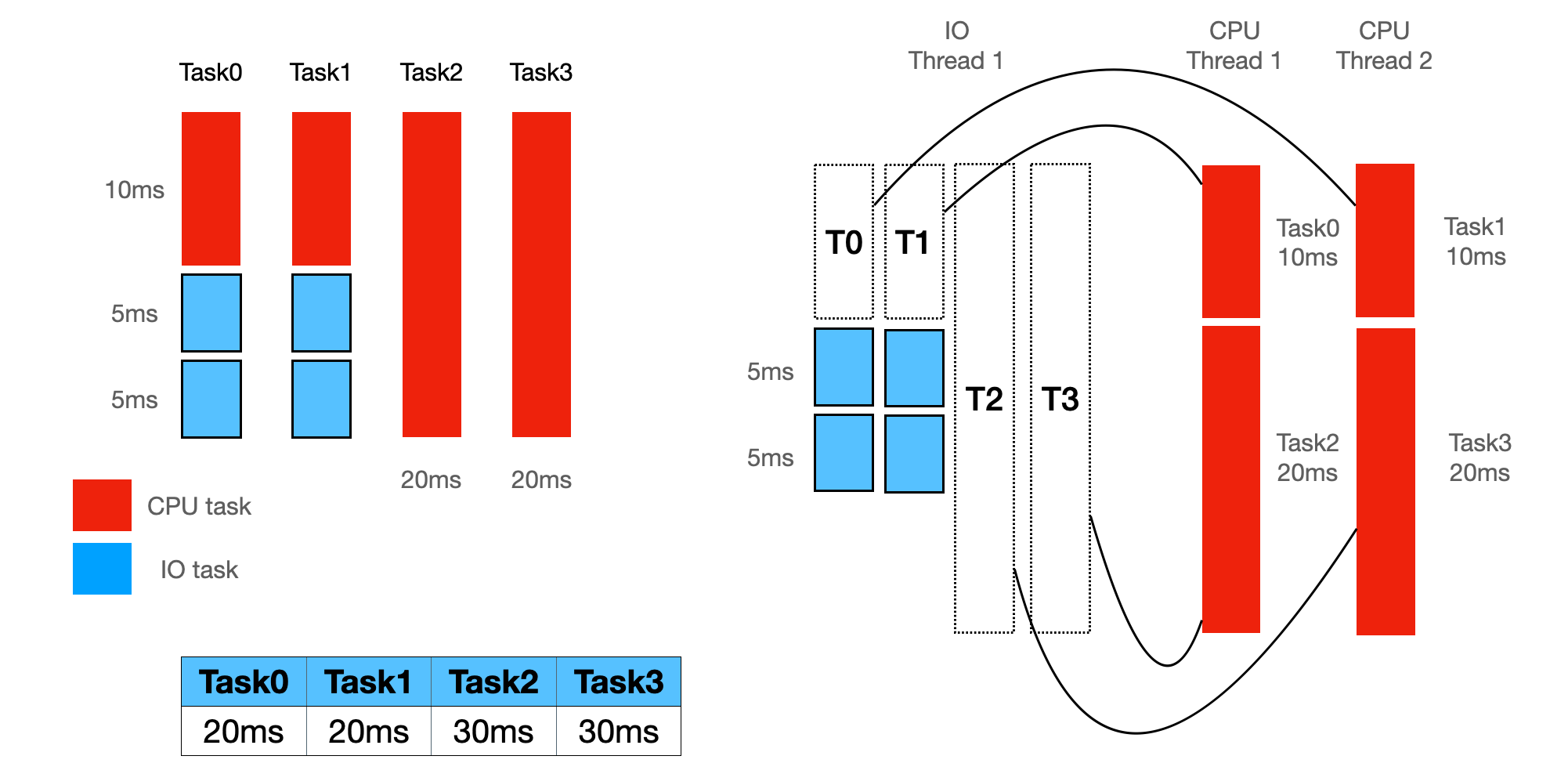
在上图中,有四个任务,分别是:
- Task0、Task1 是混合型的,里面既有 IO 型任务,又有 CPU 型任务
- Task2、Task3 是单纯的 CPU 型任务
执行方式的不同会导致任务的耗时不同,
- 图一方式,把 CPU 型与 IO 型任务混合在一个线程执行,那么最差情况下 Task0、Task1 的耗时都是 35ms
- 图二方式,把 CPU 型与 IO 型任务区分开,分两个 runtime 去执行,在这种情况下,Task0、Task1 的耗时都是 20ms
因此一般推荐通过 spawn_blocking 来执行可能需要长时间执行的任务,这样来保证 worker 线程能够尽快的获取控制权。
有了上面的知识,再来尝试分析本文一开始提出的问题,flush 与合并操作的具体内容可以用如下伪代码表示:
async fn flush() { let input = memtable.scan(); let processed = expensive_cpu_task(); write_to_s3(processed).await; } async fn compact() { let input = read_from_s3().await; let processed = expensive_cpu_task(input); write_to_s3(processed).await; } runtime1.block_on(flush); runtime2.block_on(compact);
可以看到,flush 与 compact 均存在上面说的问题, expensive_cpu_task 可能会卡主 worker 线程,进而影响读写 s3 的耗时, s3 的客户端用的是 object_store,它内部使用 reqwest 来进行 HTTP 通信。
如果 flush 和 compact 运行在一个 runtime 内,基本上就不需要额外解释了,但是这两个运行在不同的 runtime 中,是怎么导致相互影响的呢?笔者专门写了个模拟程序来复现问题,代码地址:
- https://github.com/jiacai2050/tokio-debug
模拟程序内有两个 runtime,一个来模拟 IO 场景,一个来模拟 CPU 场景,所有请求按说都只需要 50ms 即可返回,由于 CPU 场景有堵塞操作,所以实际的耗时会更久,IO 场景中没有堵塞操作,按说都应该在 50ms 左右返回,但多次运行中,均会有一两个任务耗时在 1s 上下,而且主要集中在 io-5、io-6 这两个请求上。
[2023-08-06T02:58:49.679Z INFO foo] io-5 begin [2023-08-06T02:58:49.871Z TRACE reqwest::connect::verbose] 93ec0822 write (vectored): b"GET /io-5 HTTP/1.1\r\naccept: */*\r\nhost: 127.0.0.1:8080\r\n\r\n" [2023-08-06T02:58:50.694Z TRACE reqwest::connect::verbose] 93ec0822 read: b"HTTP/1.1 200 OK\r\nDate: Sun, 06 Aug 2023 02:58:49 GMT\r\nContent-Length: 14\r\nContent-Type: text/plain; charset=utf-8\r\n\r\nHello, \"/io-5\"" [2023-08-06T02:58:50.694Z INFO foo] io-5 cost:1.015695346s
上面截取了一次运行日志,可以看到 io-5 这个请求从开始到真正发起 HTTP 请求,已经消耗了 192ms(871-679),从发起 HTTP 请求到得到响应,经过了 823ms,正常来说只需要 50ms 的请求,怎么会耗时将近 1s 呢?
给人的感觉像是 reqwest 实现的连接池出了问题,导致 IO 线程里面的请求在等待 cpu 线程里面的连接,进而导致了 IO 任务耗时的增加。通过在构造 reqwest 的 Client 时设置 pool_max_idle_per_host 为 0 来关闭连接复用后,IO 线程的任务耗时恢复正常。
笔者在这里向社区提交了这个 issue,但还没有得到任何答复,所以根本原因还不清楚。不过,通过这个按理,笔者对 Tokio 如何调度任务有了更深入的了解,这有点像 Node.js,绝不能阻塞调度线程。而且在 CeresDB 中,我们是通过添加一个专用运行时来隔离 CPU 和 IO 任务,而不是禁用链接池来解决这个问题,感兴趣的读者可以参考 PR #907。
总结
上面通过一个 CeresDB 中的生产问题,用通俗易懂的语言来介绍了 Tokio 的调度原理,真实的情况当然要更加复杂,Tokio 为了实现最大可能的低延时做了非常多细致的优化,感兴趣的读者可以参考下面的文章来了解更多内容:
最后,希望读者能够通过本文的案例,意识到 Tokio 使用时可能存在的潜在问题,尽量把 CPU 等会堵塞 worker 线程的任务隔离出去,减少对 IO 型任务的影响。