

Rust Search Extension is an indispensable browser extension for Rustaceans looking to search for docs and crates. One of its most powerful features is its ability to instantly search the top 20K crates in the address bar. But how is this achieved, and why is it so fast? In this article, we will dive into the details.

Quick demo
If you are not familiar with the extension, here is a quick demonstration of how to search the top 20K crates in the address bar.
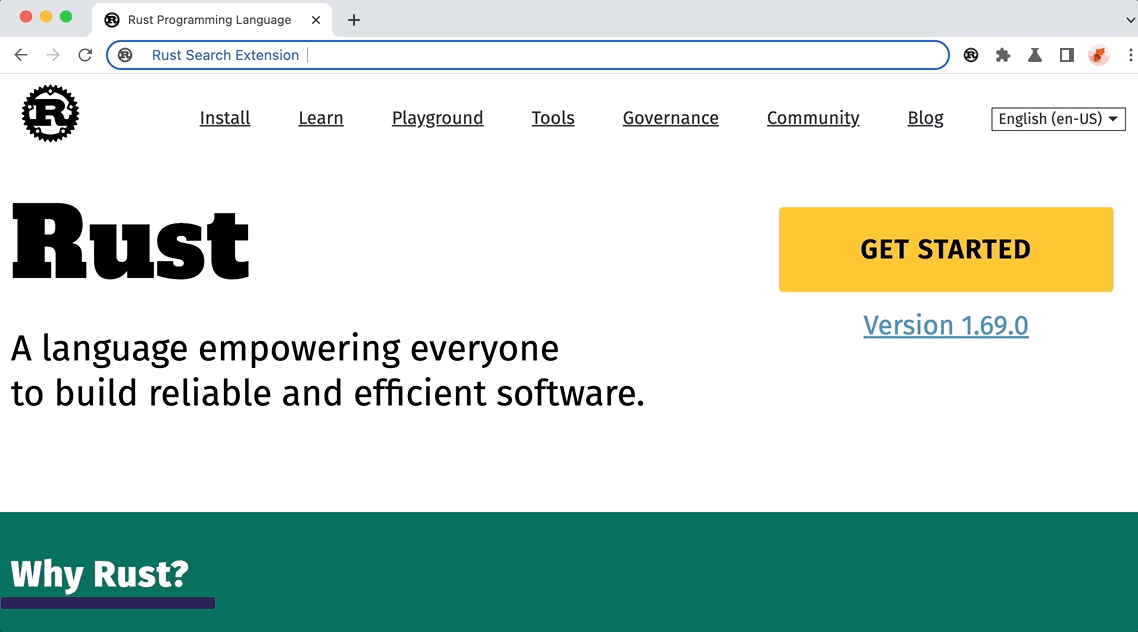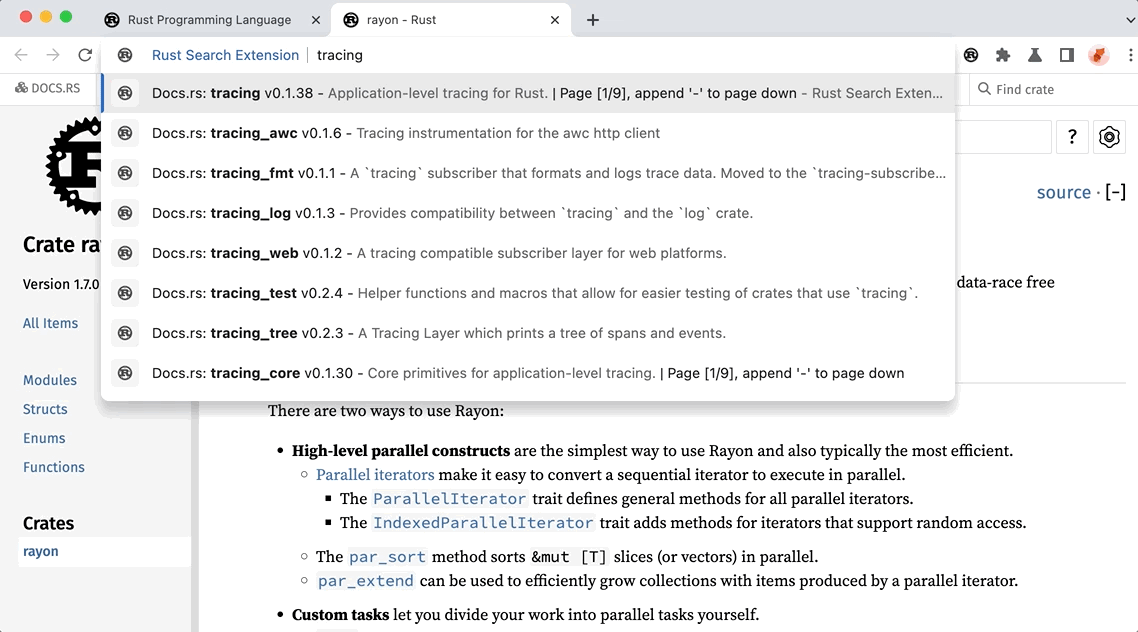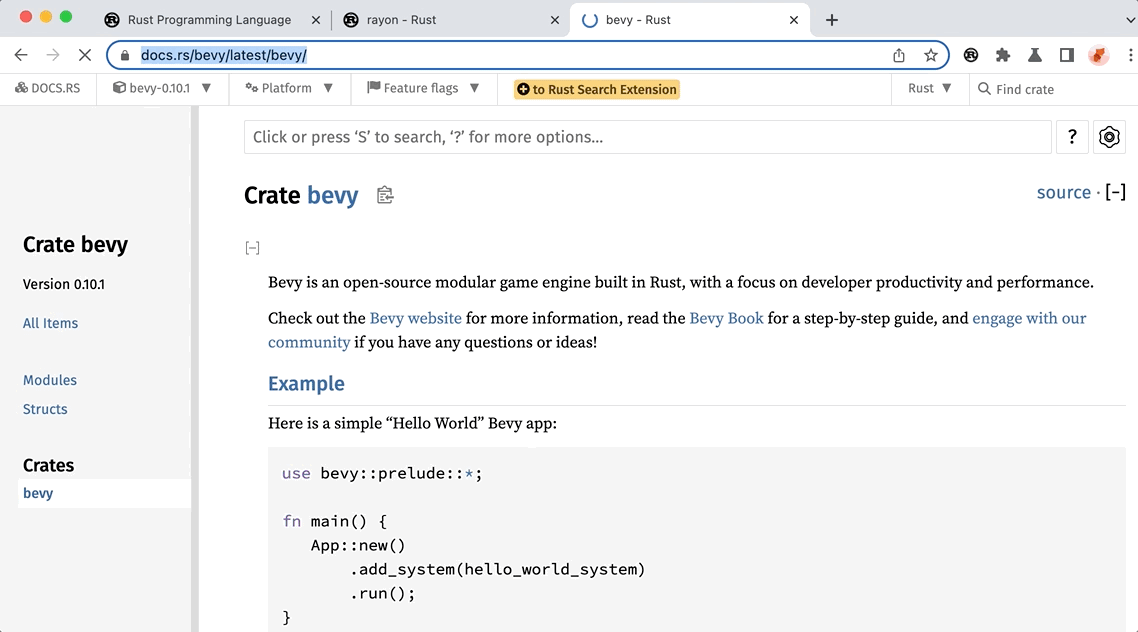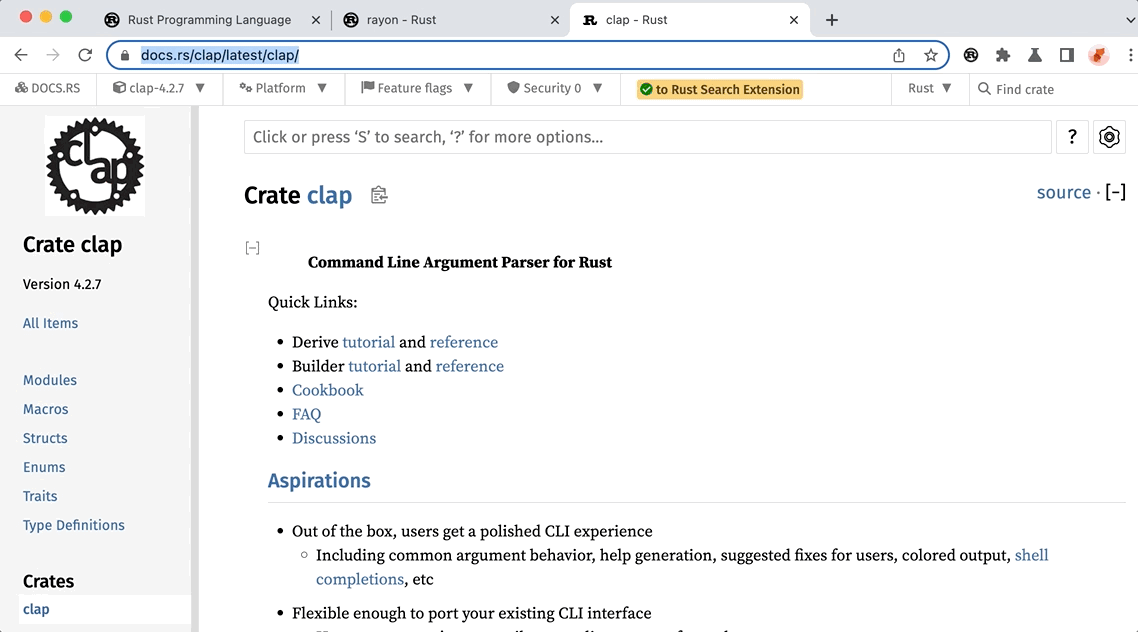
First, input rs in the address bar to activate the extension. Then, simply input the crate name or keywords you want to search for. The extension will instantly show you the top 20K crates that match your query. It is blazing fast, isn’t it? So, how is this achieved? The answer is simple: we have integrated a search index of the top 20K crates into the extension. In the next section, we will show you how we built the index and how it works.
Build top 20K crates index
To build the crates index, we need to access the database of crates.io. Fortunately, crates.io provides a public CSV database dumps that is updated every 24 hours.
The essential database schema
To build the top 20K crates index, we need access to the crates.io database schema. The schema includes several files, but we only need crates.csv to get the top 20K most downloaded crates and versions.csv to get the latest version of each crate.
Here is the directory structure of the dumped database:
$ tree . . ├── README.md ├── data │ ├── badges.csv │ ├── categories.csv │ ├── crate_owners.csv │ ├── crates.csv ✅ │ ├── crates_categories.csv │ ├── crates_keywords.csv │ ├── dependencies.csv │ ├── keywords.csv │ ├── metadata.csv │ ├── reserved_crate_names.csv │ ├── teams.csv │ ├── users.csv │ ├── version_downloads.csv │ └── versions.csv ✅ ├── export.sql ├── import.sql ├── metadata.json └── schema.sql 1 directory, 19 files
We can use xsv to quickly peek the columns of crates.csv and versions.csv:
$ xsv headers crates.csv 1 created_at 2 description ✅ 3 documentation 4 downloads ✅ 5 homepage 6 id ✅ 7 max_upload_size 8 name ✅ 9 readme 10 repository 11 updated_at $ xsv headers versions.csv 1 checksum 2 crate_id ✅ 3 crate_size 4 created_at 5 downloads 6 features 7 id 8 license 9 links 10 num ✅ 11 published_by 12 updated_at 13 yanked
Parse the database dumps
The database dumps are provided in tar.gz format, which we can extract using tar crate. Once the files are extracted, we can use csv crate to parse the CSV files.
const MAX_CRATE_SIZE: usize = 20 * 1000; #[derive(Deserialize, Debug)] struct Crate { #[serde(rename = "id")] crate_id: u64, name: String, downloads: u64, description: Option<String>, #[serde(skip_deserializing, default = "default_version")] version: Version, } #[derive(Deserialize, Debug)] struct CrateVersion { crate_id: u64, num: Version, } fn execute(&self) -> crate::Result<()> { let mut crates: Vec<Crate> = Vec::new(); let mut versions: Vec<CrateVersion> = Vec::new(); let csv_path = "db-dump.tar.gz"; let mut archive = Archive::new(Decoder::new(BufReader::new(File::open(csv_path)?))?); for file in archive.entries()? { let file = file?; if let Some(filename) = file.path()?.file_name().and_then(|f| f.to_str()) { match filename { "crates.csv" => { crates = read_csv(file)?; } "versions.csv" => { versions = read_csv(file)?; } _ => {} } } } crates.par_sort_unstable_by(|a, b| b.downloads.cmp(&a.downloads)); crates = crates.into_iter().take(MAX_CRATE_SIZE).collect(); }
We parse crates.csv and versions.csv into Vec<Crate> and Vec<CrateVersion>, respectively. We then sort the crates by downloads to get the top 20K crates.
Note: We use rayon’s par_sort_unstable_by() instead of std’s sort_unstable_by() to parallelize the sorting process.
Building the search index
While 20K items may not be a huge number for a computer to iterate through, we still need an efficient way to store and search through the crates. We can adopt the map as the format of the index, where the key is the crate name, and the value is the crate description and version.
{ "crate_name1": ["crate_description1", "crate_version1"], "crate_name2": ["crate_description2", "crate_version2"], ... }
However, we need to ensure that we get the latest version for each crate. Here is how we do it:
// A <crate_id, latest_version> map to store the latest version of each crate. let mut latest_versions = HashMap::<u64, Version>::with_capacity(versions.len()); versions.into_iter().for_each(|cv| { let num = cv.num; latest_versions .entry(cv.crate_id) .and_modify(|v| { if (*v).cmp(&num) == Ordering::Less { *v = num.clone(); } }) .or_insert(num); }); // Update the latest version of each crate. crates.iter_mut().for_each(|item: &mut Crate| { if let Some(version) = latest_versions.remove(&item.crate_id) { item.version = version; } });
Now that we have the latest version of each crate, we can generate the index.
fn generate_javascript_crates_index(crates: Vec<Crate>) -> Result<()> { // <name, [optional description, version]> let crates_map: HashMap<String, (Option<String>, Version)> = crates .into_par_iter() .map(|item| (item.name, (item.description, item.version))) .collect(); format!( "var crateIndex={};", serde_json::to_string(&crates_map).unwrap() ) let path = Path::new("./crate-index.js"); fs::write(path, &contents)?; Ok(()) }
We generate the index as a JavaScript file instead of a JSON file. Here is a sample of the generated index:
var crateInde={ "rand":["Random number generators and other randomness functionality.","0.8.5"], "tokio":["An event-driven, non-blocking I/O platform for writing asynchronous I/O backed applications.","1.27.0"] ... };
Compressing the index
The full index of top 20K crates is more than 1.7MB. Since we are going to integrate the whole index into the extension, we should compress it to reduce the size. One idea is to map most frequent words to a short token. Then we can replace the words with the token in the index. For example, the words asynchronous and applications occur frequently in the index, we can replace them with $1 and $2, respectively.
Tokenizing the search words and building the frequency map
The first step is to collect all text, including the crate name and description, and use unicode-segmentation to tokenize them into words.
use unicode_segmentation::UnicodeSegmentation; #[derive(Debug)] struct WordCollector { words: Vec<String>, } impl WordCollector { fn new() -> Self { WordCollector { words: vec![] } } fn collect_crate_name(&mut self, name: &str) { self.words.extend( name .split(|c| c == '_' || c == '-') .filter(|c| c.len() >= 3) .map(String::from) .collect::<Vec<_>>(), ) } fn collect_crate_description(&mut self, description: &str) { self.words.extend( description .trim() .unicode_words() // Tokenize the description into words. .filter(|word| word.len() >= 3) .take(100) .map(String::from) .collect::<Vec<_>>(), ); } } fn execute() -> Result<()> { // some code omitted... let mut collector = WordCollector::new(); crates.iter_mut().for_each(|item: &mut Crate| { if let Some(version) = latest_versions.remove(&item.crate_id) { // Update the latest version of the crate. item.version = version; } if let Some(description) = &item.description { collector.collect_crate_description(description); } collector.collect_crate_name(&item.name); }); // some code omitted... Ok(()) }
Then we can calculate the frequency of each word.
use unicode_segmentation::UnicodeSegmentation; #[derive(Debug)] struct FrequencyWord<'a> { word: &'a str, frequency: usize, } impl<'a> FrequencyWord<'a> { #[inline] fn score(&self) -> usize { // Due to the prefix + suffix occupying two letters, // we should minus the length to calculate the score. // This will lead to a 0.4% reduction in file size. (self.word.len() - 2) * self.frequency } } impl WordCollector { // Get the most frequent words. fn get_frequency_words(self) -> Vec<FrequencyWord> { // A word to frequency mapping. Such as <"cargo", 100>. let mut frequency_mapping: HashMap<String, usize> = HashMap::new(); self.words.into_iter().for_each(|word| { let count = frequency_mapping.entry(word).or_insert(0); *count += 1; }); let mut frequency_words = frequency_mapping .into_par_iter() .map(|(word, frequency)| FrequencyWord { word, frequency }) .collect::<Vec<FrequencyWord>>(); frequency_words.par_sort_by_key(|b| Reverse(b.score())); frequency_words } }
The final frequency_words is sorted by the score, which is calculated by the word length and frequency. Here is the sample of the frequency_words:
[ FrequencyWord { word: "asynchronous", frequency: 100 }, FrequencyWord { word: "applications", frequency: 99 }, FrequencyWord { word: "generators", frequency: 98 }, ... ]
Build the token map
The next step is to build the token map. We can achieve this by combining a prefix and suffix of characters to form each token. The prefix can be a set of special characters, such as @$^&, while the suffix can be a combination of alphanumeric characters.
#[derive(Debug)] pub struct Minifier<'a> { // A word to keys mapping. Such as <"cargo", "$0">. mapping: HashMap<&'a str, String>, } impl<'a> Minifier<'a> { const PREFIX: &'static str = "@$^&"; const SUFFIX: &'static str = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"; pub fn new(frequency_words: &'a [FrequencyWord]) -> Minifier<'a> { let keys: Vec<String> = Self::PREFIX .chars() .flat_map(|prefix| { Self::SUFFIX .chars() .map(|suffix| format!("{prefix}{suffix}")) .collect::<Vec<String>>() }) .collect(); let words = frequency_words .into_par_iter() .take(keys.len()) .collect::<Vec<_>>(); Minifier { mapping: words .into_par_iter() .enumerate() .map(|(index, fw)| (fw.word.as_str(), keys.get(index).unwrap().to_owned())) .collect(), } } }
The Minifier will generate a mapping from the word to the token. Here is a sample of the resulting mapping:
{ "asynchronous": "$1", "applications": "$2", "generators": "$3", ... }
Replace the words with tokens
The last step is to replace the words with tokens in the index.
impl<'a> Minifier<'a> { pub fn minify_crate_name(&self, name: &str) -> String { let vec: Vec<&str> = name .split(|c| c == '_' || c == '-') .map(|item| self.mapping.get(item).map(Deref::deref).unwrap_or(item)) .collect(); vec.join("_") } pub fn minify_description(&self, description: &str) -> String { description .split_word_bounds() .map(|item| self.mapping.get(item).map(Deref::deref).unwrap_or(item)) .collect() } }
After the minification, the crate index will be like this:
var mapping=JSON.parse('{ "@2":"for", "@6":"and", "@E":"format", "@s":"applications", "@y":"platform", ..., "$U":"tokio", "$W":"plugin", "$w":"writing" }'); var crateIndex={ "rand":["Random number generators @6 other randomness @E.","0.8.5"], "$U":["An event-driven, non-blocking I/O @y @2 $w @W I/O backed @s.","1.27.0"], ... };
We also include the mapping field in the index, so that tokens can be decoded back to their corresponding words.
Another thing worth mentioning is that we also use minifier crate to minify the crateIndex JavaScript object to reduce the file size further. After minification, the file size is reduced to 1.3MB, more than 20% smaller than the original index. The resulting minified index can be found at https://rust.extension.sh/crates/index.js.
$ ls -l -rw-r--r-- 1 root 1339340 Mar 11 21:27 crates-with-minified.js -rw-r--r-- 1 root 1664707 Mar 11 17:06 crates-without-minified.js
Keeping the index up-to-date
Since the index is generated from the crates.io API, it needs to be updated regularly to ensure that it reflects the latest state of the Rust ecosystem. We can use GitHub Actions to schedule the updates. The user can also manually trigger an update by entering the :update command or visiting the update page on the Rust Search Extension website.
Conclusion
In this article, we have described how to build a top 20K crates index for Rust and how to minimize the index to reduce its file size. The source code for the index generation and minimization process is available on GitHub. The Rust Search Extension is a powerful tool for searching the Rust crates ecosystem, and we hope that this article has provided some insight into how it works behind the scenes.
Thanks for reading, and welcome to give Rust Search Extension a try!